From Dimensionality Reduction to Natural Language Generation (NLG)
- Dimensionality reduction: Simplifying complex datasets
- Speech recognition: Teaching machines to understand human speech
- Backpropagation: Training neural networks to improve performance
- Supervised learning: Teaching machines through labeled data
- Knowledge representation: Organizing information for AI systems
- Natural language generation (NLG): Creating human-like text
Are you feeling overwhelmed by the multitude of AI jargon? Struggling to make sense of terms like dimensionality reduction, speech recognition, backpropagation, supervised learning, knowledge representation, and natural language generation (NLG)? Look no further, because RSe Global has got you covered!
In this article, we will delve into the world of artificial intelligence and break down these complex concepts into understandable, bite-sized chunks. Whether you're a newcomer to AI or an industry expert, our aim is to provide you with a comprehensive understanding of these key terms that are crucial to the field.
Dimensionality reduction: Simplifying complex datasets
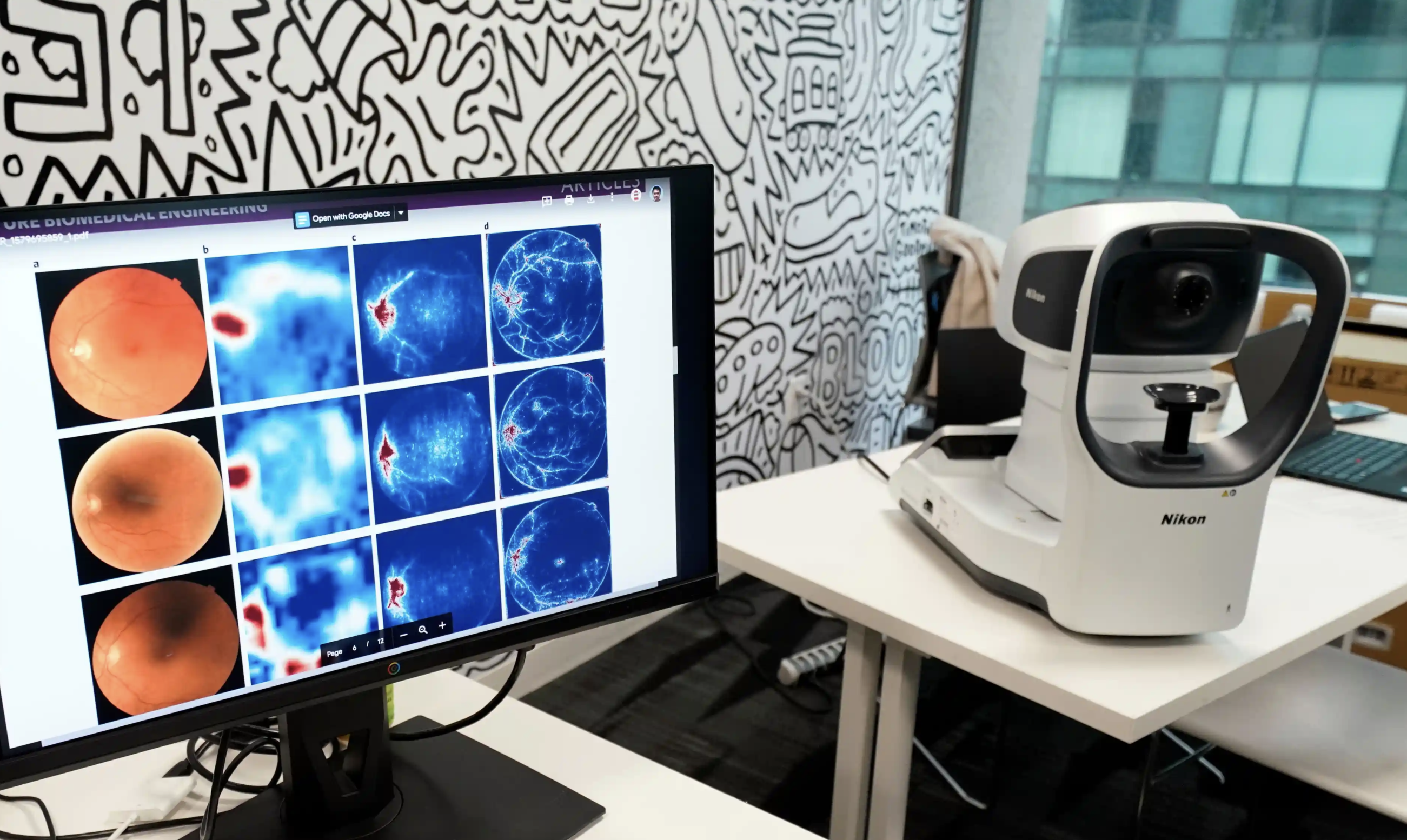
Dimensionality reduction is a technique used to simplify complex datasets by reducing the number of input variables without losing too much information. In other words, it helps us analyze and interpret large sets of data more effectively. The main goal of dimensionality reduction is to eliminate irrelevant features and find the most informative ones that contribute the most to the overall understanding of the data.
One popular dimensionality reduction technique is Principal Component Analysis (PCA). PCA identifies the directions, or principal components, along which the data varies the most. By projecting the data onto these components, it is possible to reduce the dimensionality while retaining as much of the original information as possible. Another technique is t-SNE (t-Distributed Stochastic Neighbor Embedding), which is particularly useful for visualizing high-dimensional data in a lower-dimensional space.
Dimensionality reduction plays a crucial role in various fields, including image and speech recognition, natural language processing, and recommendation systems. By reducing the dimensionality of the data, we can improve the efficiency and accuracy of AI algorithms, making them more practical and scalable.
Speech recognition: Teaching machines to understand human speech
Speech recognition technology has revolutionized the way we interact with devices, making voice commands a reality. It is the ability of a machine to understand and interpret human speech and convert it into a written or digital form. Speech recognition systems can be found in devices like smartphones, smart speakers, and even cars, enabling users to dictate messages, search the web, or control devices with voice commands.
The process of speech recognition involves several steps. First, the audio signal is captured and converted into a digital format. Then, the signal is preprocessed to remove noise and enhance speech features. Next, the preprocessed signal is analyzed using various techniques, such as Hidden Markov Models (HMMs) or Deep Neural Networks (DNNs), to recognize phonemes, words, and sentences. Finally, the recognized speech is converted into text or used for further processing.
Speech recognition is a challenging task due to the variability of human speech, including accents, dialects, and background noise. However, advancements in machine learning and deep learning algorithms have significantly improved the accuracy and robustness of speech recognition systems. Today, speech recognition technology is widely used in various applications, such as virtual assistants, transcription services, and voice-controlled devices.
Backpropagation: Training neural networks to improve performance
Backpropagation is a fundamental algorithm for training neural networks, enabling them to learn from their mistakes and improve their performance over time. It is based on the concept of gradient descent, which involves iteratively adjusting the weights and biases of a neural network to minimize the difference between the predicted output and the desired output.
The backpropagation algorithm consists of two main phases: the forward pass and the backward pass. In the forward pass, the input data is fed into the neural network, and the activations are computed layer by layer until the output is obtained. Then, the difference between the predicted output and the desired output is calculated and used to determine the error. In the backward pass, the error is propagated back through the network, and the gradients of the weights and biases are computed using the chain rule of calculus. Finally, the weights and biases are updated based on the computed gradients, and the process is repeated until the desired level of performance is achieved.
Backpropagation has been a key factor in the success of deep learning, allowing neural networks to learn complex patterns and solve a wide range of tasks, such as image classification, natural language processing, and speech recognition. It is a computationally intensive process, but advancements in hardware and parallel computing have made it feasible to train deep neural networks on large datasets.
Supervised learning: Teaching machines through labeled data
Supervised learning is a machine learning technique where an algorithm learns from labeled examples to make predictions or decisions. In supervised learning, the input data is accompanied by the correct output, or label, which serves as a guide for the learning process. The goal is to train a model that can accurately map new inputs to the correct outputs.
The process of supervised learning involves several steps. First, a labeled dataset is created, where each example consists of an input and the corresponding output. Then, the dataset is split into a training set and a test set. The training set is used to train the model, while the test set is used to evaluate its performance. During training, the algorithm learns from the labeled examples by adjusting its internal parameters, such as weights and biases, to minimize the prediction error. Once the model is trained, it can be used to make predictions on new, unseen data.
Supervised learning is widely used in various domains, including image and speech recognition, natural language processing, and predictive analytics. It is particularly useful when the desired output is known and can be easily obtained, such as in classification or regression tasks. However, it requires a large amount of labeled data, which can be time-consuming and expensive to obtain. Nonetheless, advancements in data collection and annotation techniques have made it easier to create labeled datasets, enabling the development of more accurate and robust machine learning models.
Knowledge representation: Organizing information for AI systems
Knowledge representation is the process of organizing information in a way that can be effectively used by AI systems. It involves modeling the knowledge and relationships within a domain to enable reasoning, problem-solving, and decision-making. The goal of knowledge representation is to capture the relevant information in a structured form that can be easily processed by AI algorithms.
There are various techniques and formalisms for knowledge representation, including semantic networks, frames, ontologies, and rule-based systems. Semantic networks represent knowledge as a network of interconnected nodes, where each node represents a concept or an entity, and the edges represent the relationships between them. Frames are similar to semantic networks but provide a more structured representation by defining attributes and slots for each concept. Ontologies, on the other hand, provide a more formal and standardized representation of knowledge by defining concepts, properties, and relationships using a specific language, such as the Web Ontology Language (OWL). Rule-based systems use logical rules to represent knowledge and make inferences based on them.
Knowledge representation is crucial for AI systems to understand and reason about the world. It allows machines to acquire, store, and manipulate knowledge, enabling them to solve complex problems and make informed decisions. By organizing information in a structured form, knowledge representation facilitates the development of intelligent systems that can learn, adapt, and interact with humans in a meaningful way.
Natural language generation (NLG): Creating human-like text
Natural language generation (NLG) is a subfield of artificial intelligence that focuses on the generation of human-like text from structured data or other forms of input. It involves converting data into coherent and grammatically correct sentences, paragraphs, or even longer pieces of text. NLG is used in various applications, such as chatbots, virtual assistants, content generation, and personalized recommendations.
NLG systems can generate text using different approaches, including rule-based methods, template-based methods, and machine learning-based methods. Rule-based methods involve defining grammatical rules and patterns to generate text based on the input data. Template-based methods use pre-defined templates that can be filled with the input data to generate text. Machine learning-based methods, on the other hand, learn the patterns and structures of natural language from a large corpus of text and use that knowledge to generate new text.
NLG has the potential to transform the way we interact with computers and machines. By enabling machines to generate human-like text, NLG systems can facilitate communication, provide personalized experiences, and automate content creation. However, creating high-quality and coherent text is still a challenging task, and further advancements in natural language processing and machine learning are needed to improve the performance of NLG systems.
RSe Global: Your AI-Co Pilot and Navigator through market tempests
Embrace the opportunities that AI presents, and remember that RSe Global is here to support you on your AI journey.
We at RSe Global believe not that AI should be aimed at replacing investment managers but rather harnessed as a ‘Quantamental’ augmentation of their deep expertise and decision-making capabilities, equipping them with tools that expose them to the ‘best of both worlds’ that the interface between man and machine has to offer. Join us in our journey to help navigate the fiercest market tempests and reclaim your precious time to focus on value-generation for clients.
Follow us on LinkedIn, and explore our ground-breaking suite of tools here and join the future of investing.
#investmentmanagementsolution #investmentmanagement #machinelearning #AIinvestmentmanagementtools #DigitalTransformation #FutureOfFinance #AI #Finance